mysql同步到flink解决数据归档问题(二)终极篇 | 数据库论坛-大发黄金版app下载
mysql 数据归档操作手册:使用 flink cdc 技术
上个文章提到mysql存储过大需要备份后再删除元数据,但有时候为了保持数据的完整性,该怎样解决呢,为了解决这个问题,可以考虑使用 flink cdc 技术将历史数据归档,以减轻主数据库的负担并提高性能。以下是详细的实现原理、优缺点分析及操作手册。
插叙:我是实战效果
- 准备一台已经安装了docker的linux,实体机环境也可以。
使用下面的内容创建一个docker-compose.yml文件:[root@localhost online-flink]# more docker-compose.yml version: '2.1' services: postgres: image: debezium/example-postgres:1.1 ports: - "5432:5432" environment: - postgres_db=postgres - postgres_user=postgres - postgres_password=postgres mysql: image: debezium/example-mysql:1.1 ports: - "3306:3306" environment: - mysql_root_password=123456 - mysql_user=mysqluser - mysql_password=mysqlpw elasticsearch: image: elastic/elasticsearch:7.6.0 environment: - cluster.name=docker-cluster - bootstrap.memory_lock=true - "es_java_opts=-xms512m -xmx512m" - discovery.type=single-node ports: - "9200:9200" - "9300:9300" ulimits: memlock: soft: -1 hard: -1 nofile: soft: 65536 hard: 65536 kibana: image: elastic/kibana:7.6.0 ports: - "5601:5601" [root@localhost online-flink]# - 启动程序: flink-1.13.2

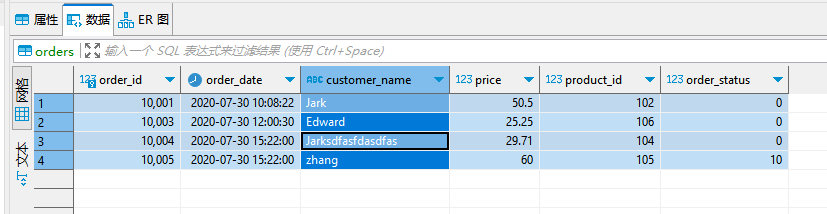
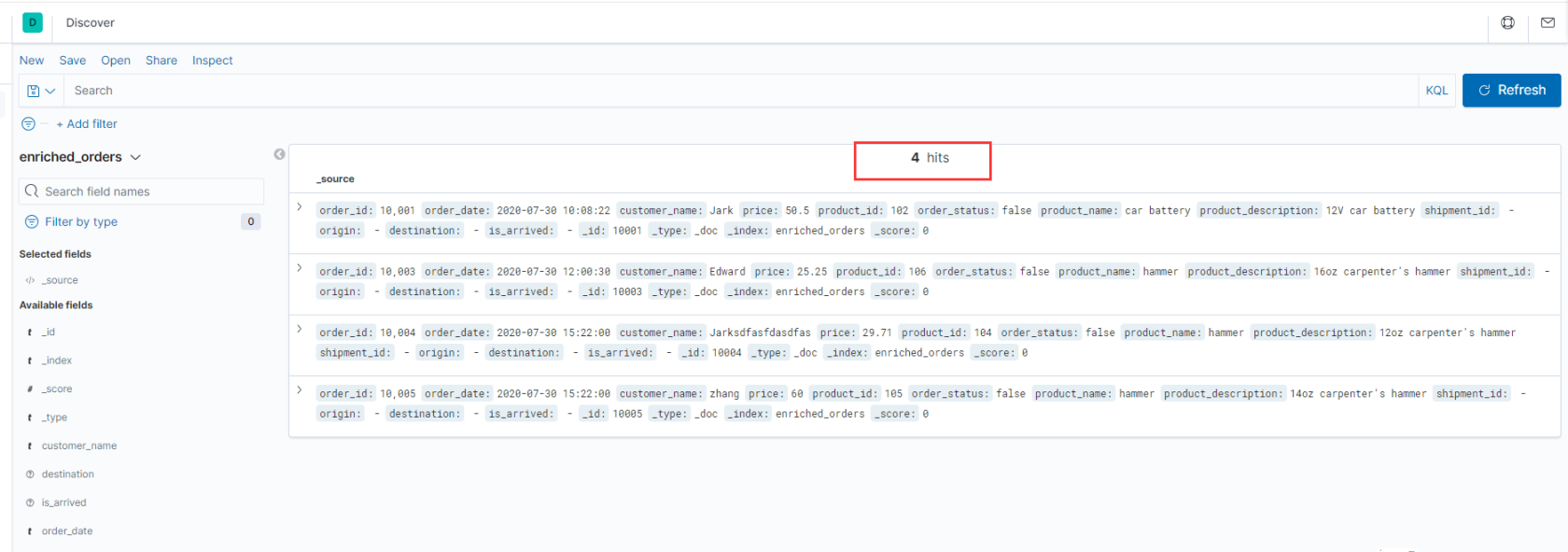
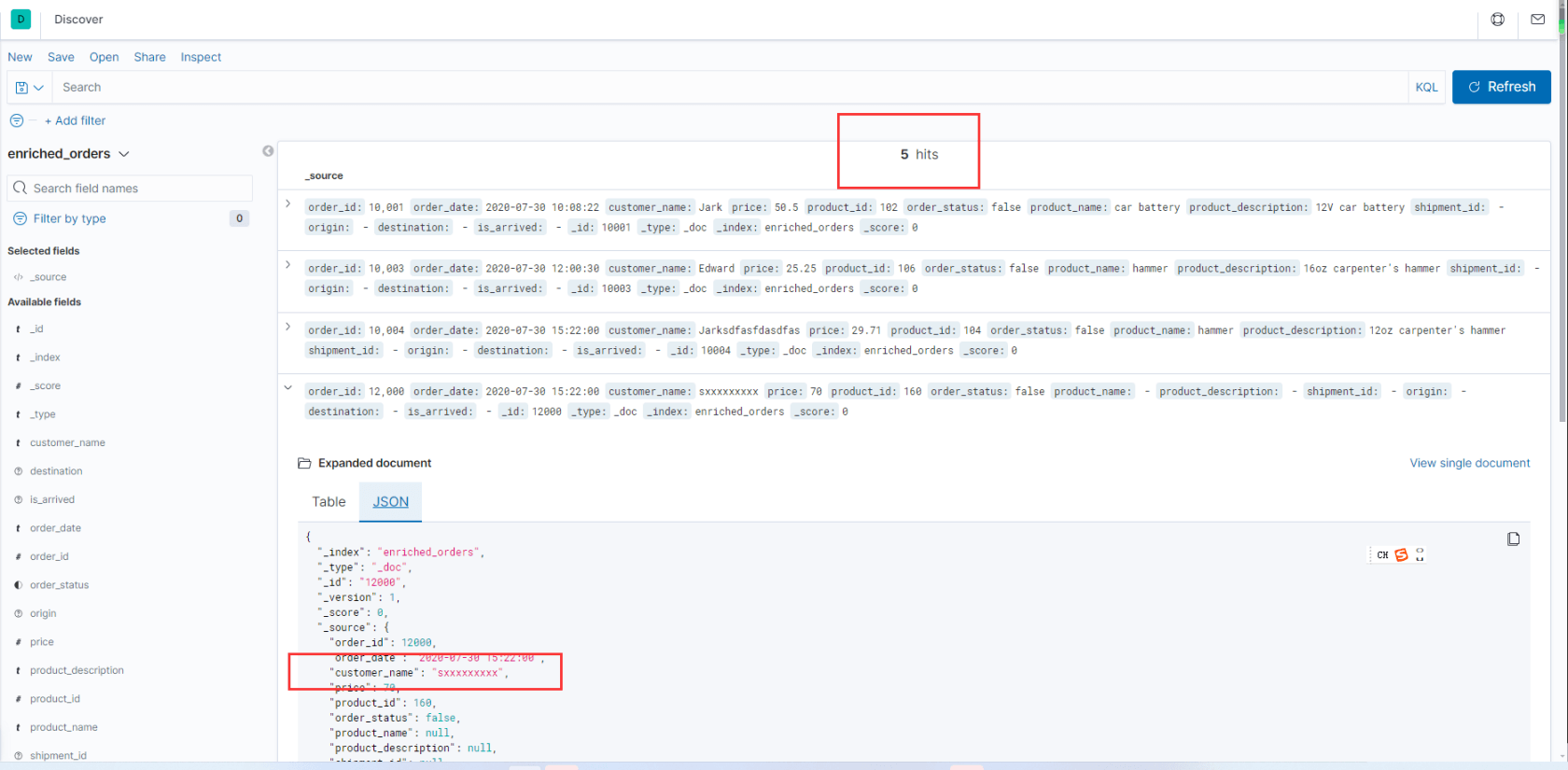
**数据变化时,es变化效果: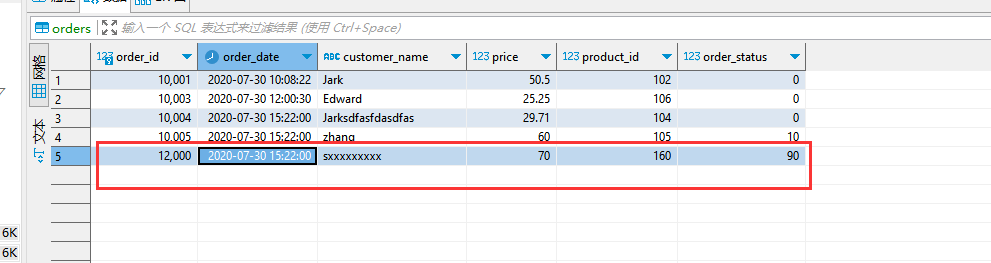
一、实现原理
- 数据提取:
- 使用 flink cdc(change data capture)技术连接 mysql 数据库,实时捕获数据变更。flink cdc 能够监听数据库的变更事件,包括插入、更新和删除操作,具体通过监听 mysql 的 binlog(binary log)来完成。
- 变更数据捕获(cdc):flink cdc 通过 binlog 捕获 mysql 数据库中所有更改的日志。mysql 的 binlog 记录了插入、更新、删除等所有操作。
- 连接 mysql:使用 mysql jdbc 驱动程序建立与 mysql 的连接,提供必要的数据库信息(如主机、端口、用户名和密码)。
- 配置 cdc 来源:通过 flink 的 source api,指定 mysql 为数据源,并设置监控的数据库和表,以捕获特定的数据。
- 数据类型映射:flink 根据 mysql 表的模式自动识别数据类型,进行内部映射,以确保后续处理中的数据类型不出现错误。
- 事件流:一旦配置完毕,flink 开始监控 binlog 中的数据变更事件,这些事件会以数据流的形式被处理。
- 数据筛选:
- 在提取过程中,可以根据业务需求筛选出需要归档的数据,例如依据时间戳、状态等条件选择历史数据。
- 数据转换:
- 对提取的数据进行适当的转换,以适应 elasticsearch 或其他存储系统的格式要求,可能包括字段重命名、数据类型转化、格式化等。
- 数据存储:
- 将筛选及转换后的数据存储到低成本的存储系统,如冷存储(hdfs、aws s3 等)或归档数据库。
- 主数据库清理:
- 在确认数据成功归档后,从 mysql 中删除已归档的数据,以减少主数据库的负担。
二、优缺点分析
优点:
- 性能提升:
- 通过将历史数据归档,可以显著减轻 mysql 数据库的压力,优化数据查询性能,改善应用接口的响应时间。
- 实时更新:
- 使用 flink cdc,能够实现对数据变更的实时响应,确保归档过程中的数据一致性。
- 灵活存储:
- 归档数据可以选择更便宜的存储大发黄金版app下载的解决方案,降低存储成本。
缺点:
- 归档数据可以选择更便宜的存储大发黄金版app下载的解决方案,降低存储成本。
- 实现复杂性:
- 引入 flink 和 cdc 的技术栈增加了系统的复杂度,可能需要更多的开发和维护资源。
- 延迟风险:
- 在归档过程中,数据在 mysql 与目标存储之间的传输可能会导致延迟,需考虑系统的实时性需求。
- 数据恢复:
- 如果需要从归档数据中恢复信息,可能会涉及更多操作和时间,增加数据管理难度。
三、操作手册
以下是实现数据归档的详细步骤:
1. 环境准备
- 确保 mysql 数据库和目标存储(如 hdfs 或 s3)已部署并可访问。
- 安装并配置 apache flink 和 flink cdc。
- 配置 flink 和 elasticsearch(或其他目标存储)的连接器。
2. 数据提取与处理
- 连接 mysql:
- 使用 flink cdc 连接到 mysql 数据库,以便捕获变更事件。
- 编写 flink 作业:
- 在 flink 中创建数据流作业,提取所需的数据并应用筛选条件。
- 例如,提取创建设备日期早于某个日期的数据。
3. 数据转换
- 数据格式转换:
- 对提取的数据进行转换,确保符合目标存储的格式要求。此过程可以包括字段重命名、数据映射等。
4. 数据存储
- 对提取的数据进行转换,确保符合目标存储的格式要求。此过程可以包括字段重命名、数据映射等。
- 写入目标存储:
- 将处理后的数据写入到目标存储系统,如 elasticsearch 或其他归档数据库。
- 确认数据完整性:
- 在完成数据写入后,进行数据完整性检查以确保归档成功。
5. 清理主数据库
- 删除已归档数据:
- 从 mysql 中删除已成功归档的数据,以释放空间并提高性能。
6. 监控与维护
- 从 mysql 中删除已成功归档的数据,以释放空间并提高性能。
- 监控 flink 作业:
- 监控 flink 作业的运行状态,确保数据流动的正常进行。
- 定期评估:
- 定期评估数据归档策略,根据业务需求调整数据归档频率和策略。
结论
通过本操作手册,可以有效地将数据从 mysql 归档至低成本存储,提高查询性能,确保用户体验。使用 flink cdc 技术的实时性和灵活性,能够优化系统整体架构。运行过程中,需注意系统复杂性和数据恢复的问题,以便维护数据的完整性和一致性。
参考手册:
源代码及插件都包含在内获取:
我用夸克网盘分享了「flink1.13.2.7z」,点击链接即可保存。打开「夸克app」,无需下载在线播放视频,畅享原画5倍速,支持电视投屏。
链接:
提取码:hra5
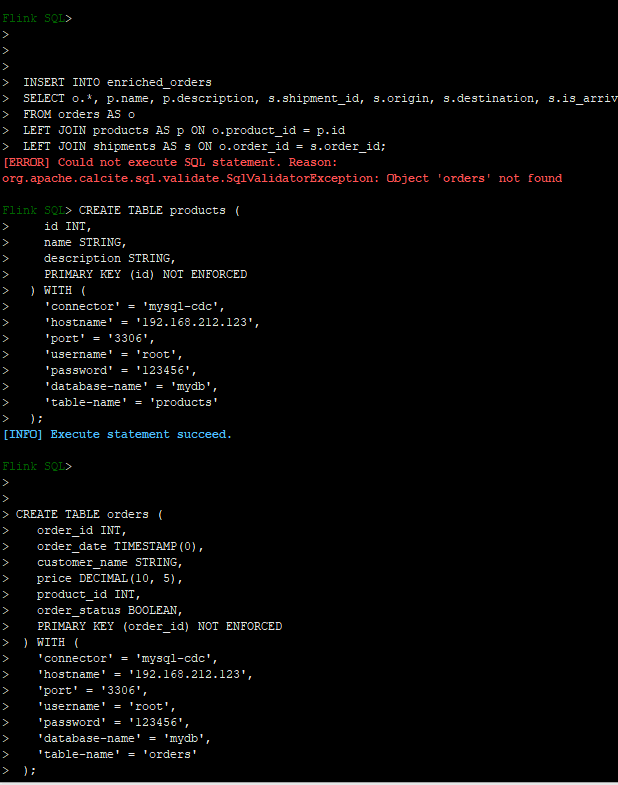
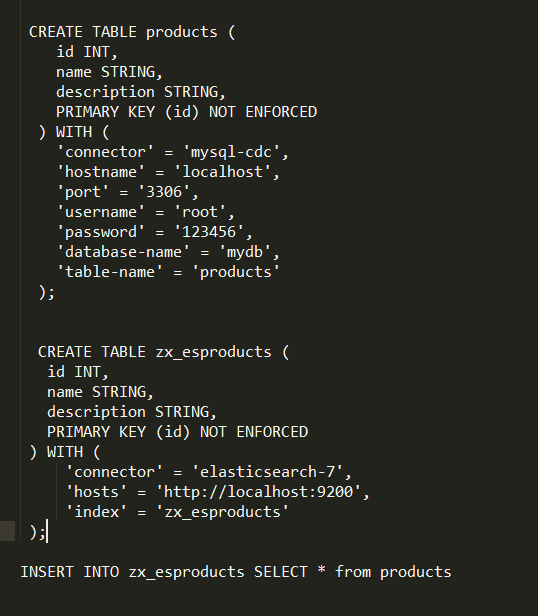
补充一下sql
create table products (
id int,
name string,
description string,
primary key (id) not enforced
) with (
'connector' = 'mysql-cdc',
'hostname' = '192.168.212.123',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'database-name' = 'mydb',
'table-name' = 'products'
);
create table orders (
order_id int,
order_date timestamp(0),
customer_name string,
price decimal(10, 5),
product_id int,
order_status boolean,
primary key (order_id) not enforced
) with (
'connector' = 'mysql-cdc',
'hostname' = '192.168.212.123',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'database-name' = 'mydb',
'table-name' = 'orders'
);
create table shipments (
shipment_id int,
order_id int,
origin string,
destination string,
is_arrived boolean,
primary key (shipment_id) not enforced
) with (
'connector' = 'postgres-cdc',
'hostname' = '192.168.212.123',
'port' = '5432',
'username' = 'postgres',
'password' = 'postgres',
'database-name' = 'postgres',
'schema-name' = 'public',
'table-name' = 'shipments'
);
create table enriched_orders (
order_id int,
order_date timestamp(0),
customer_name string,
price decimal(10, 5),
product_id int,
order_status boolean,
product_name string,
product_description string,
shipment_id int,
origin string,
destination string,
is_arrived boolean,
primary key (order_id) not enforced
) with (
'connector' = 'elasticsearch-7',
'hosts' = 'http://192.168.212.123:9200',
'index' = 'enriched_orders'
);
本作品采用《cc 协议》,转载必须注明作者和本文链接
